引言
豆瓣电影作为国内知名的电影评分与评论平台,其Top 250榜单一直备受影迷关注。对于数据分析爱好者或电影研究者而言,获取这份榜单的数据进行进一步分析无疑具有极高的价值。那么,豆瓣电影Top 250的爬虫代码是什么?如何编写并运行这样的爬虫呢?本文将为你详细解答。
什么是豆瓣电影Top 250爬虫?
豆瓣电影Top 250爬虫是一种自动化程序,它模拟浏览器行为,访问豆瓣电影Top 250页面,抓取页面上的电影信息(如电影名称、评分、简介、导演、主演等),并将这些信息保存到本地或数据库中,以便后续分析使用。
如何编写豆瓣电影Top 250爬虫代码?
编写豆瓣电影Top 250爬虫代码需要一定的编程基础,通常使用Python语言结合一些第三方库(如requests、BeautifulSoup、Scrapy等)来实现。以下是一个简单的示例代码,展示了如何使用requests和BeautifulSoup库来抓取豆瓣电影Top 250的数据。
步骤一:安装必要的库
首先,你需要确保你的Python环境中安装了requests和BeautifulSoup库。如果尚未安装,可以通过以下命令进行安装:
pip install requests beautifulsoup4步骤二:编写爬虫代码
接下来,你可以编写一个Python脚本来抓取豆瓣电影Top 250的数据。以下是一个简单的示例代码:
import requests
from bs4 import BeautifulSoup
def get_douban_top250():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
url = 'https://movie.douban.com/top250'
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
movies = []
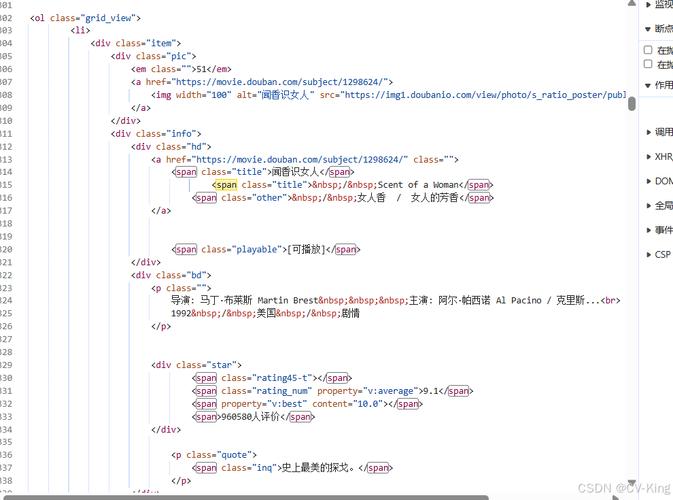
for item in soup.select('.grid_view .item'):
rank = item.find('em').get_text()
title = item.find('span', class_='title').get_text()
rating_num = item.find('span', class_='rating_num').get_text()
quote = item.find('span', class_='inq').get_text() if item.find('span', class_='inq') else ''
movies.append({
'rank': rank,
'title': title,
'rating_num': rating_num,
'quote': quote
})
return movies
if __name__ == '__main__':
top250_movies = get_douban_top250()
for movie in top250_movies:
print(f"排名: {movie['rank']}, 电影名称: {movie['title']}, 评分: {movie['rating_num']}, 引用: {movie['quote']}")步骤三:运行爬虫代码
将上述代码保存为一个Python文件(如douban_top250_crawler.py),然后在命令行中运行该文件:
python douban_top250_crawler.py运行后,你将看到豆瓣电影Top 250的排名、电影名称、评分以及引用等信息被打印到控制台。
如何优化爬虫代码?
虽然上述示例代码能够抓取豆瓣电影Top 250的基本信息,但在实际应用中,你可能还需要对爬虫代码进行优化,以提高抓取效率和稳定性。以下是一些优化建议:
- 异常处理:添加异常处理机制,以应对网络请求失败、页面结构变化等情况。
- 分页抓取:豆瓣电影Top 250是分页显示的,你可能需要编写代码来抓取所有分页的数据。
- 数据去重:在抓取过程中,可能会遇到重复数据,可以通过设置唯一标识(如电影ID)来去除重复项。
- 使用代理IP:为了避免因频繁访问而被豆瓣封禁IP,可以使用代理IP来隐藏真实IP地址。
- 数据库存储:将抓取到的数据保存到数据库中,以便后续分析和查询。
结语
通过本文的介绍,相信你已经了解了如何编写并运行一个简单的豆瓣电影Top 250爬虫代码。当然,这只是一个起点,你可以根据自己的需求对爬虫进行进一步的优化和扩展。无论是数据分析、学术研究还是个人兴趣探索,爬虫技术都能为你提供强大的数据支持。
爬虫技术虽然强大,但请务必遵守相关法律法规和网站的使用条款,不要进行恶意抓取或滥用数据。