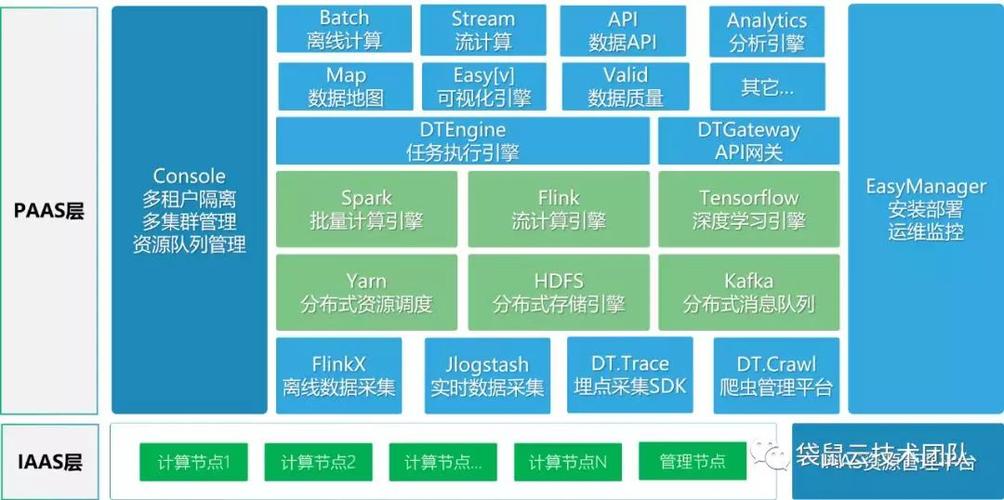
大数据技术栈:构建高效数据驱动的决策引擎
在当今这个数据爆炸的时代,大数据技术栈成为了企业实现数字化转型、提升业务效率与洞察力的关键。一个完整且高效的大数据技术栈涵盖了从数据采集、存储、处理到分析、可视化的全过程。本文将深入探讨大数据技术栈的各个组成部分,帮助您理解如何构建一个强大的数据驱动的决策引擎。
一、数据采集层
数据采集是大数据技术栈的基石,它负责从各种源头获取数据。这包括但不限于:
- 日志收集工具:如Flume、Logstash,用于收集服务器日志、应用日志等。
- API接口:通过RESTful API或GraphQL等协议从第三方服务获取数据。
- 消息队列:如Kafka、RabbitMQ,用于处理实时数据流。
- ETL工具:如Talend、Informatica,用于数据的抽取、转换和加载。
二、数据存储层
数据存储层负责高效、安全地保存采集到的数据。常见的数据存储技术包括:
- 关系型数据库:如MySQL、PostgreSQL,适用于结构化数据的存储。
- NoSQL数据库:如MongoDB、Cassandra,适用于半结构化或非结构化数据的存储。
- 分布式文件系统:如HDFS(Hadoop Distributed File System),用于大规模数据的存储。
- 列式数据库:如HBase、Parquet,优化大数据查询性能。
三、数据处理层
数据处理层负责清洗、转换和分析数据,为后续的数据分析提供高质量的数据集。关键技术包括:
- 批处理框架:如Hadoop MapReduce、Apache Spark,适用于大规模数据的离线处理。
- 流处理框架:如Apache Flink、Apache Storm,用于实时数据流的处理。
- 数据清洗与转换工具:如Apache NiFi、Pentaho Data Integration,用于数据的预处理。
四、数据分析与挖掘层
这一层是大数据技术栈的核心,负责从数据中提取有价值的信息和模式。主要技术包括:
- 统计分析工具:如R语言、Python(Pandas、NumPy库),用于基本的数据统计分析。
- 机器学习框架:如TensorFlow、PyTorch,用于构建和训练机器学习模型。
- 数据挖掘算法:如关联规则挖掘(Apriori算法)、聚类分析(K-means算法),用于发现数据中的隐藏模式。
五、数据可视化与报表层
数据可视化是将分析结果以直观、易懂的方式呈现给用户的关键步骤。常用技术包括:
- 可视化工具:如Tableau、Power BI,提供丰富的图表和仪表板功能。
- 开源可视化库:如D3.js、ECharts,允许开发者自定义可视化效果。
- 报表工具:如JasperReports、Pentaho Reporting,用于生成专业的报表。
总结
大数据技术栈是一个复杂而庞大的体系,涵盖了从数据采集到数据可视化的全过程。构建一个高效的数据驱动的决策引擎,需要精心选择并整合这些技术,以满足企业的具体需求。随着技术的不断发展,大数据技术栈也将持续演进,为企业带来更多的价值和创新机会。
在这个数据为王的时代,掌握大数据技术栈,就是掌握了未来的竞争力。