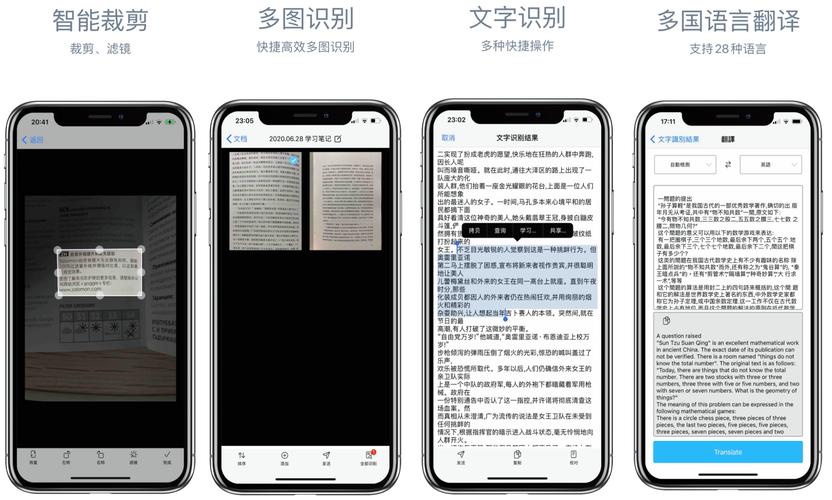
引言
在数字化时代,信息以惊人的速度增长,而文字作为信息传递的重要载体,广泛存在于各种媒介中。然而,面对海量的纸质文档、图片中的文字信息,如何高效、准确地将其转化为可编辑的电子文本,成为了一个亟待解决的问题。这时,OCR(Optical Character Recognition,光学字符识别)文字识别软件应运而生,它如同一把智能钥匙,解锁了图像中的文字信息,极大地提升了信息处理的效率与便捷性。
OCR技术原理
OCR技术通过图像处理和模式识别算法,将图像中的文字转化为计算机可编辑的文本格式。其基本原理包括以下几个步骤:
- 预处理:对输入的图像进行去噪、二值化、倾斜校正等处理,以提高后续识别的准确性。
- 字符分割:将图像中的文字区域分割成单个字符或单词,便于后续识别。
- 特征提取:提取每个字符或单词的特征信息,如轮廓、笔画等。
- 模式匹配:将提取的特征与预定义的字符模板进行匹配,识别出对应的文字。
- 后处理:对识别结果进行校正和优化,如纠正错别字、调整格式等。
OCR文字识别软件的应用场景
OCR文字识别软件因其强大的功能,被广泛应用于各个领域:
- 文档数字化:将纸质文档快速转化为电子文档,便于存储、检索和分享。
- 档案管理:对历史档案进行数字化处理,提高档案管理效率和安全性。
- 无障碍阅读:将图像中的文字转化为语音或放大显示,帮助视障人士获取信息。
- 数据录入:自动化处理表单、发票等文档中的数据录入,减少人工错误和成本。
- 智能翻译:结合翻译软件,实现多语言文档的快速翻译。
OCR文字识别软件的选择与评估
在选择OCR文字识别软件时,用户应关注以下几个方面:
- 识别准确率:软件能否准确识别各种字体、大小和风格的文字。
- 处理速度:软件处理图像的速度是否满足实际需求。
- 兼容性:软件是否支持多种图像格式和操作系统。
- 易用性:软件界面是否友好,操作是否简便。
- 安全性:软件在处理敏感信息时是否具备足够的安全保障。
市场主流OCR软件简介
目前市场上存在多款优秀的OCR文字识别软件,如:
- Adobe Acrobat:作为PDF处理领域的佼佼者,其OCR功能强大且准确。
- ABBYY FineReader:以其高识别率和丰富的功能著称,适用于各种复杂的文档识别需求。
- Tesseract OCR:开源软件,免费且易于集成,适合开发者进行二次开发。
- Google Drive OCR:集成在Google Drive中,方便用户在线识别和处理文档。
未来展望
随着人工智能技术的不断发展,OCR文字识别软件将在识别准确率、处理速度、智能化程度等方面持续提升。未来,我们有望看到更加高效、智能的OCR解决方案,为各行各业的信息处理带来更多便利和可能性。
OCR文字识别软件,作为连接图像与文本世界的桥梁,正以其独特的魅力改变着我们的工作方式和生活习惯。在这个信息爆炸的时代,让我们携手OCR技术,共同探索更加高效、智能的信息处理新纪元。